Trace format
The WTA trace format conists of 7 objects: Workload, Workflow, Tasks, TaskState, Resource, ResourceState, and DataTransfer. Each of the objects contains their a version field to enable contained updates and a unique set of properties. The format and relations between objects can best be oserved in the figure below.
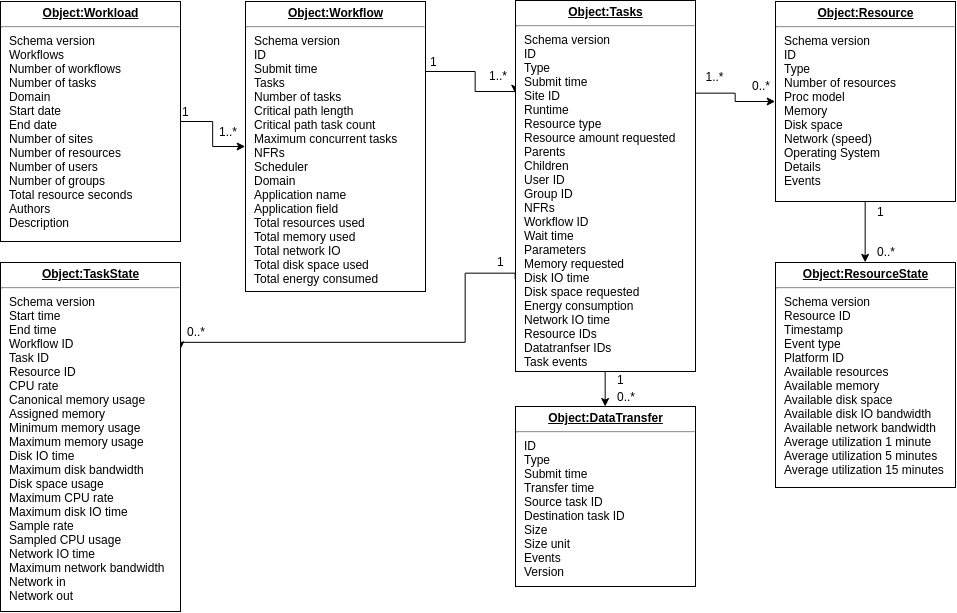
The data is offered in parquet format, compressed using the Snappy compression algorithm. Parquet is the de facto columnar standard in Big Data, and is much alike SQL tables and Pandas Dataframes in Python. Parquet reading libraries exist in many popular languages, including Java and Python.
Parse scripts
The WTA offers several parse scripts to parse other trace formats. All parse scripts are available on our GitHub wta-tools repository. The current parse scripts include, but may not be limited to:
- Pegasus trace databases
- Alibaba's 2018 cluster trace
- Old Askalon Grid workflow format
- New Askalon Cloud workflow format
- Shell's Chronos IoT workflow format
- Google's cluster traces (2014)
- SPEC ICPE traces
- LANL's Mustang trace log
- LANL's Trinity trace log
- Two Sigma workflow traces
- WorkflowHub workflow traces